Manually scrape data using browser extensions
Overview
Teaching: 45 min
Exercises: 20 minQuestions
How can I get started scraping data off the web?
How can I use XPath to more accurately select what data to scrape?
Objectives
Introduce the Chrome Scraper extension.
Practice scraping data that is well structured.
Use XPath queries to refine what needs to be scraped when data is less structured.
Using the Scraper Chrome extension
Now we are finally ready to do some web scraping. Let’s go back to the list of MPPs in the Legislative Assembly of Ontario.
We are interested in downloading this list to a spreadsheet, with columns for names and constituencies. Do do so, we will use the Scraper extension in the Chrome browser (refer to the Setup section for help installing these tools).
Scrape similar
With the extension installed, we can select the first row of the Current MPPs table right click and choose “Scrape similar” from the contextual menu:
Alternatively, the “Scrape similar” option can also be accessed from the Scraper extension icon:
Either operation will bring up the Scraper window:
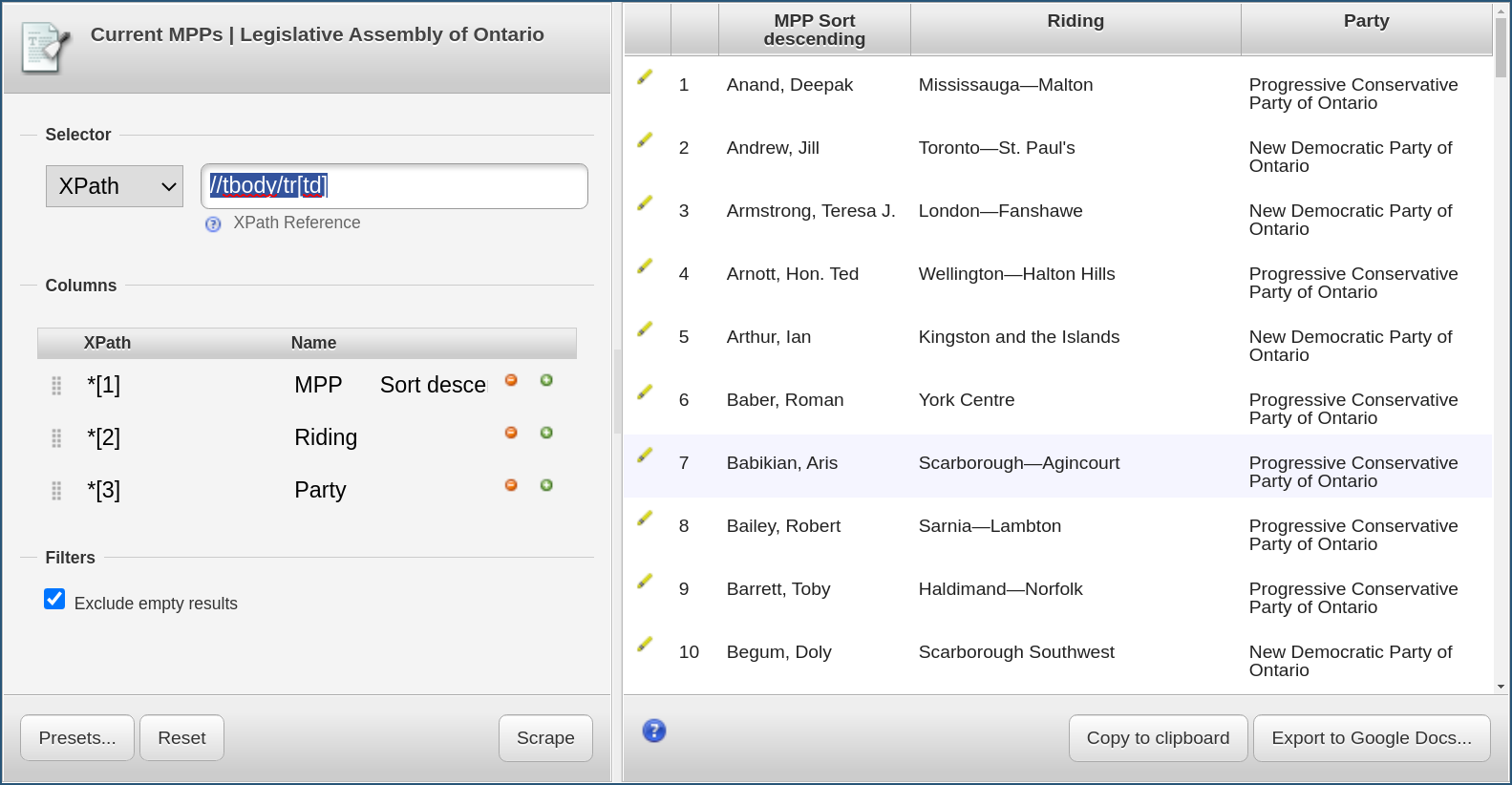
We recognize that Scraper has generated XPath queries that corresponds to the data we had
selected upon calling it. The Selector (highlighted in red in the above screenshot)
has been set to //tbody/tr[td] which selects
all the rows of the table, delimiting the data we want to extract.
In fact, we can try out that query using the technique that we learned in the previous section by typing the following in the browser console:
$x("//tbody/tr[td]")
returns something like
<- Array [672]
which we can explore in the console to make sure this is the right data.
Scraper also recognized that there were two columns in that table, and has accordingly
created two such columns (highlighted in blue in the screenshot),
each with its own XPath selector, *[1] and *[2].
To understand what this means, we have to remember that XPath queries are relative to the
current context node. The context node has been set by the Selector query above, so
those queries are relative to the array of tr elements that has been selected.
We can replicate their effect by trying out
$x("//tbody/tr[td]/*[1]")
in the console. This should select only the first column of the table. The same goes for the second column.
But in this case, we don’t need to fiddle with the XPath queries too much, as Scraper was able to deduce them for us, and we can use the export functions to either create a Google Spreadsheet with the results, or copy them into the clipboard in Tab Separated Values (TSV) format for pasting into a text document, a spreadsheet or Open Refine.
There is one bit of data cleanup we might want to do, though. If we paste the data copied from Scraper into a text document, we see something like this:
MPP Riding Party
Anand, Deepak Mississauga—Malton Progressive Conservative Party of Ontario
Andrew, Jill Toronto—St. Paul's New Democratic Party of Ontario
Armstrong, Teresa J. London—Fanshawe New Democratic Party of Ontario
Arnott, Hon. Ted Wellington—Halton Hills Progressive Conservative Party of Ontario
This is because there are a lot of unnecessary white spaces in the HTML that’s behind that table, which
are being captured by Scraper. We can however tweak the XPath column selectors to take advantage of the
normalize-space XPath function:
normalize-space(*[1])
normalize-space(*[2])
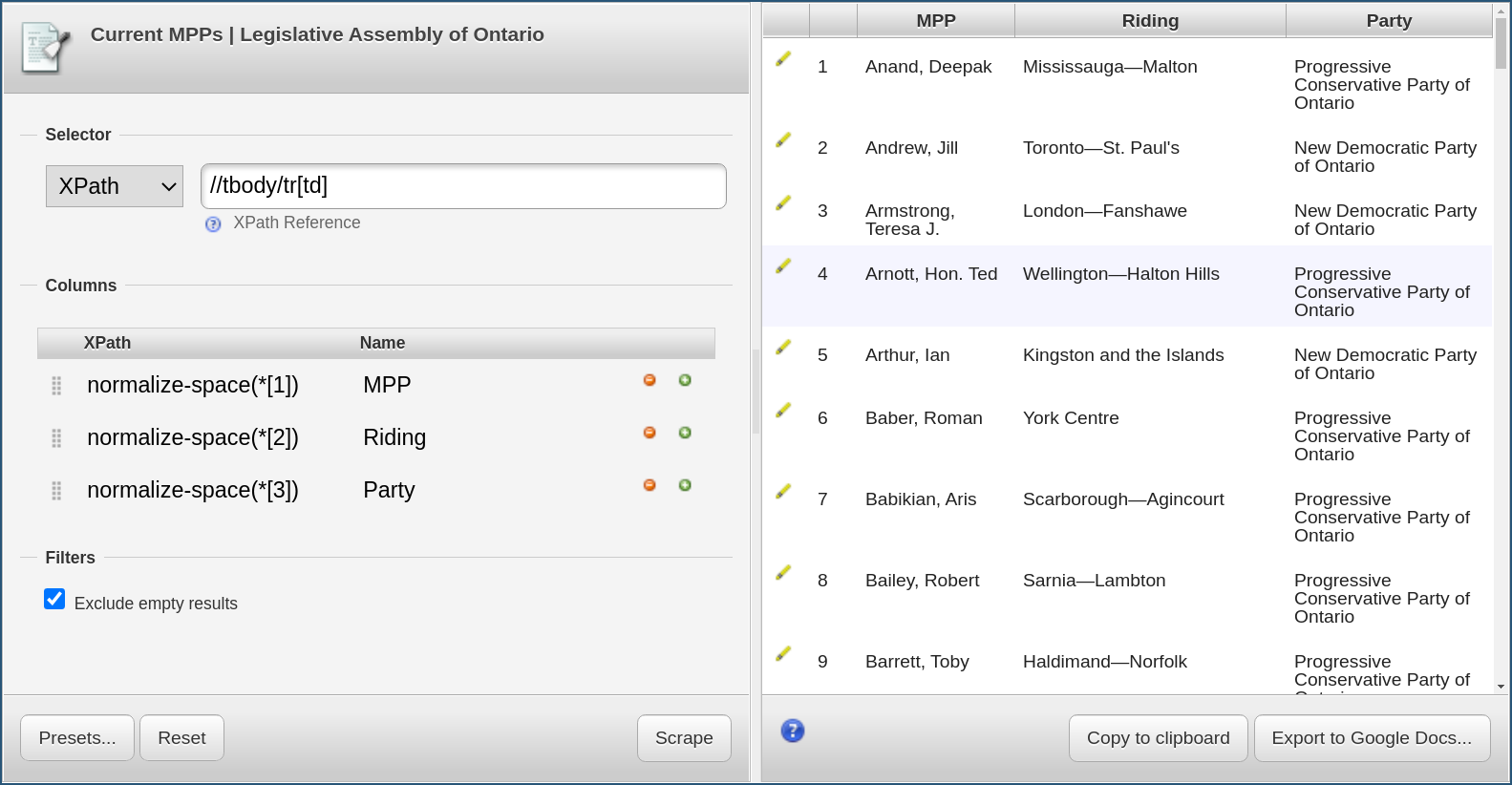
We now need to tell Scraper to scrape the data again by using our new selectors, this is done by clicking on the “Scrape” button. The preview will not noticeably change, but if we now copy again the results and paste them in our text editor, we should see
MPP Riding Party
Anand, Deepak Mississauga—Malton Progressive Conservative Party of Ontario
Andrew, Jill Toronto—St. Paul's New Democratic Party of Ontario
Armstrong, Teresa J. London—Fanshawe New Democratic Party of Ontario
Arnott, Hon. Ted Wellington—Halton Hills Progressive Conservative Party of Ontario
which is a bit cleaner.
Scrape the list of Ontario MPPs
Use Scraper to export the list of current members of the Ontario Legislative Assembly and try exporting the results in your favourite spreadsheet or data analysis software.
Once you have done that, try adding a third column containing the URLs that are underneath the names of the MPPs and that are leading to the detail page for each parliamentarian.
Tips:
- To add another column in Scraper, use the little green “+” icon in the columns list.
- Look at the source code and try out XPath queries in the console until you find what you are looking for.
- The syntax to select the value of an attribute of the type
<element attribute="value">iselement/@attribute.- The
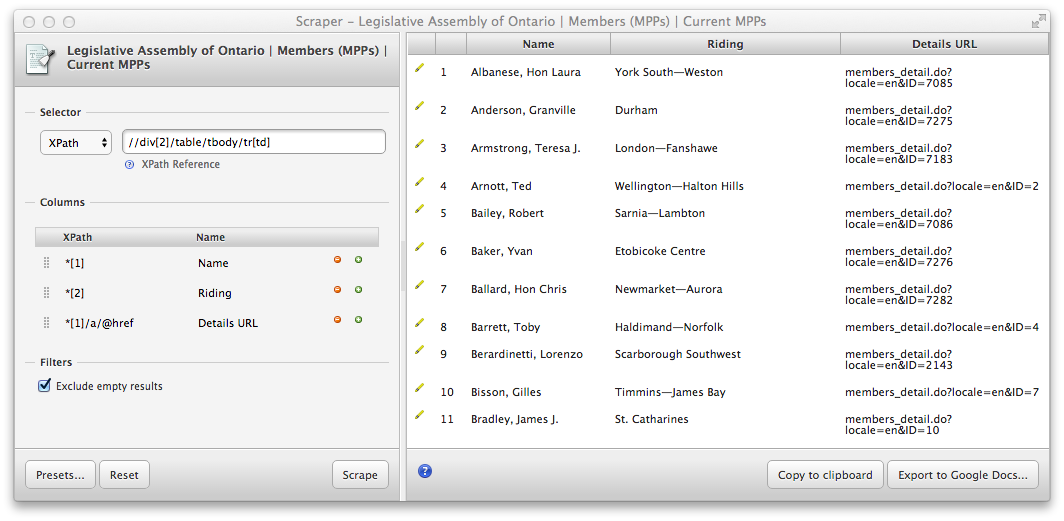
concat()XPath function can be use to concatenate things.Solution
Add a third column with the XPath query
*[1]/a/@href
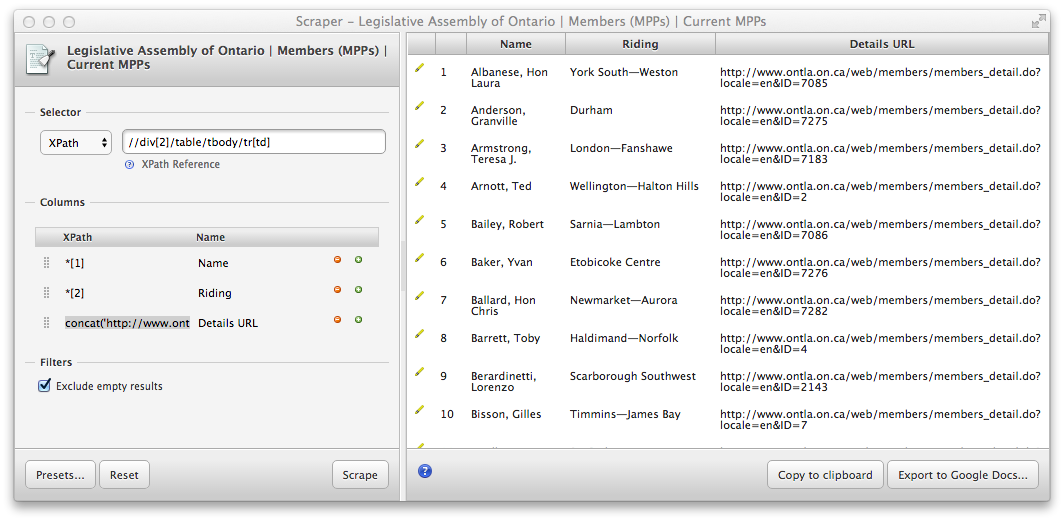
This extracts the URLs, but as luck would have it, those URLs are relative to the list page (i.e. they are missing
https://www.ola.org/en/members/current). We can use theconcat()XPath function to construct the full URLs:concat('https://www.ola.org',*[1]/a/@href)
Custom XPath queries
Sometimes, however, we do have to do a bit of work to get Scraper to select the data elements that we are interested in.
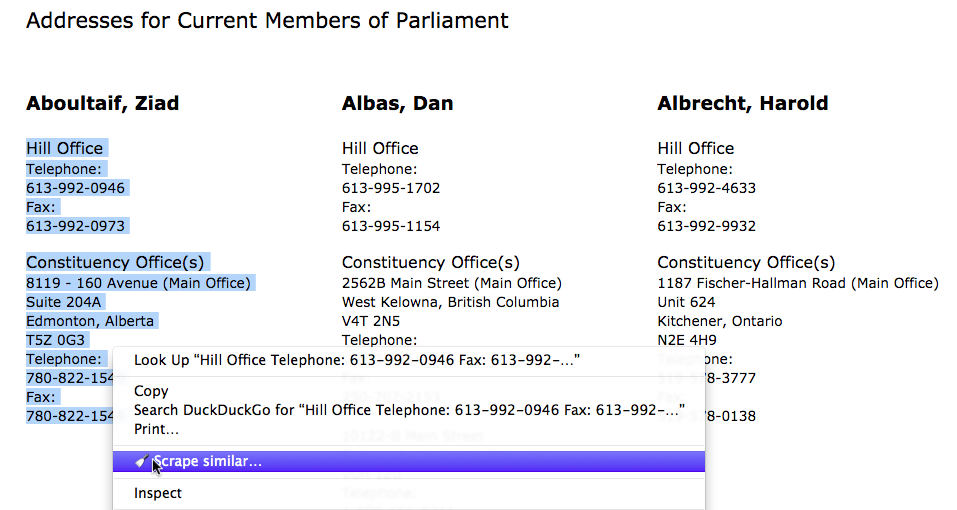
Going back to the example of the Canadian Parliament we saw in the introduction, there is a page on the same website that lists the mailing addresses of all parliamentarians. We are interested in scraping those addresses.
If we select the addresses for the first MP and try the “Scrape similar” function…
Scraper produces this:
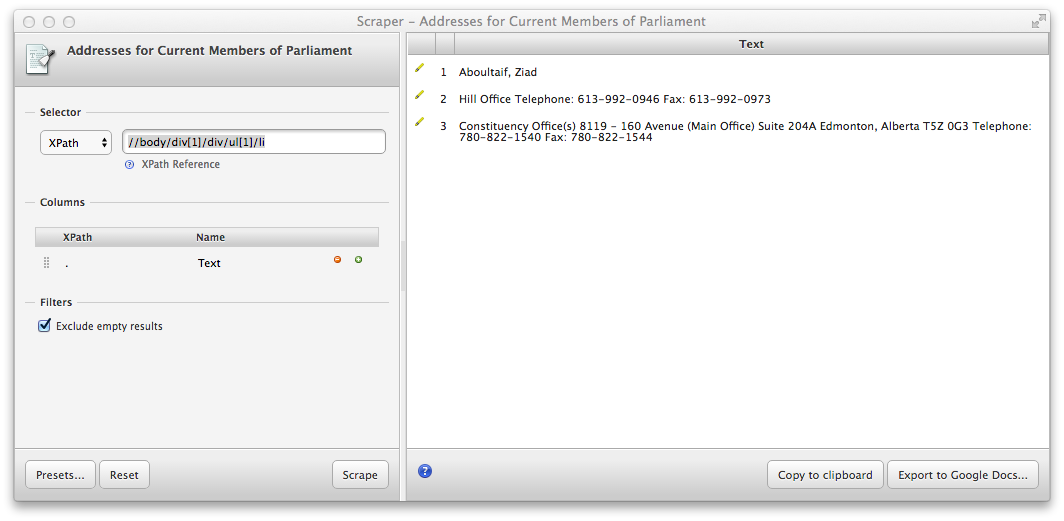
which does a nice job separating the address elements, but what if instead we want a table of the addresses of all MPs? Selecting multiple addresses instead does not help. Remember what we said about computers not being smart about structuring information? This is a good example. We humans know what the different blocks of texts on the screen mean, but the computer will need some help from us to make sense of it.
We need to tell Scraper what exactly to scrape, using XPath.
If we look at the HTML source code of that page, we see that individual MPs are all within ul
elements:
(...)
<ul>
<li><h3>Aboultaif, Ziad</h3></li>
<li>
<span class="addresstype">Hill Office</span>
<span>Telephone:</span>
<span>613-992-0946</span>
<span>Fax:</span>
<span>613-992-0973</span>
</li>
<li>
<ul>
<li><span class="addresstype">Constituency Office(s)</span></li>
<li>
<span>8119 - 160 Avenue (Main Office)</span>
<span>Suite 204A</span>
<span>Edmonton, Alberta</span>
<span>T5Z 0G3</span>
<span>Telephone:</span> <span>780-822-1540</span>
<span>Fax:</span> <span>780-822-1544</span>
<span class="spacer"></span>
</li>
</ul>
</li>
</ul>
(...)
So let’s try changing the Selector XPath in Scraper to
//body/div[1]/div/ul
and hit “Scrape”. We get something that is closer to what we want, with one line per MP, but the addresses are still all in one block of unstructured text:
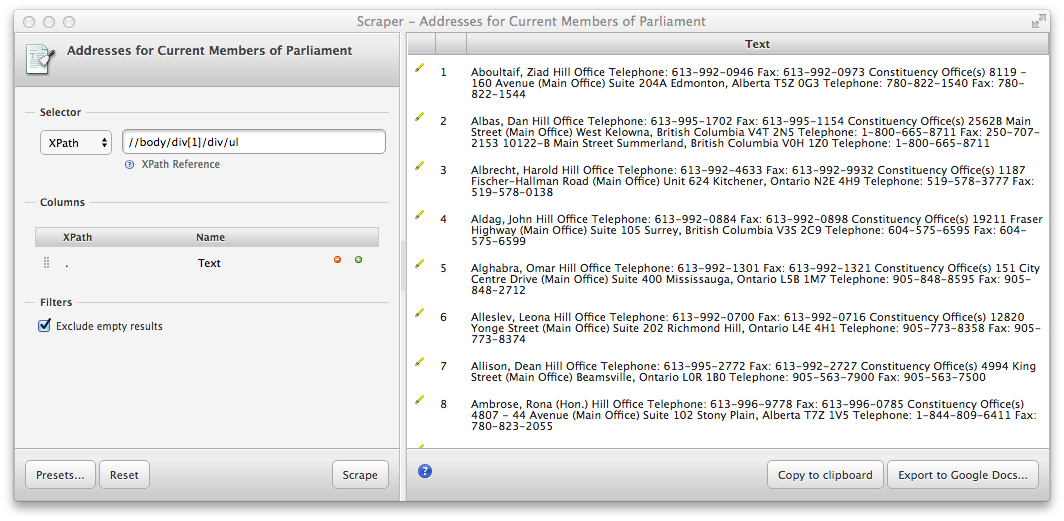
Looking closer at the HTML source, we see that name and addresses are separated by li elements
within those ul elements. So let’s add a few columns based on those elements:
./li[1] -> Name
./li[2] -> Hill Office
./li[3] -> Constituency
This produces the following result:
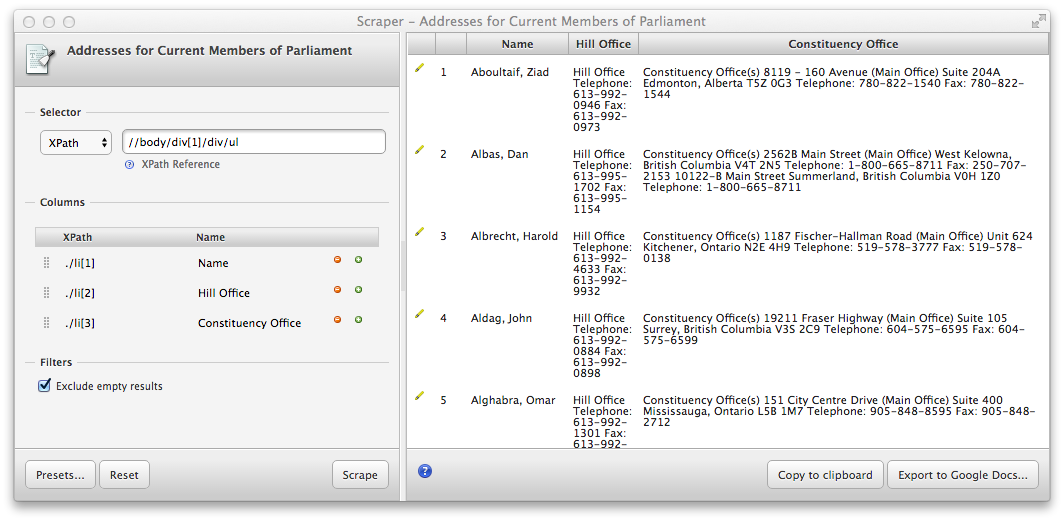
The addresses are still one big block of text each, but at least we now have a table for all MPs and the addresses are separated.
Scrape the Canadian MPs’ phone numbers
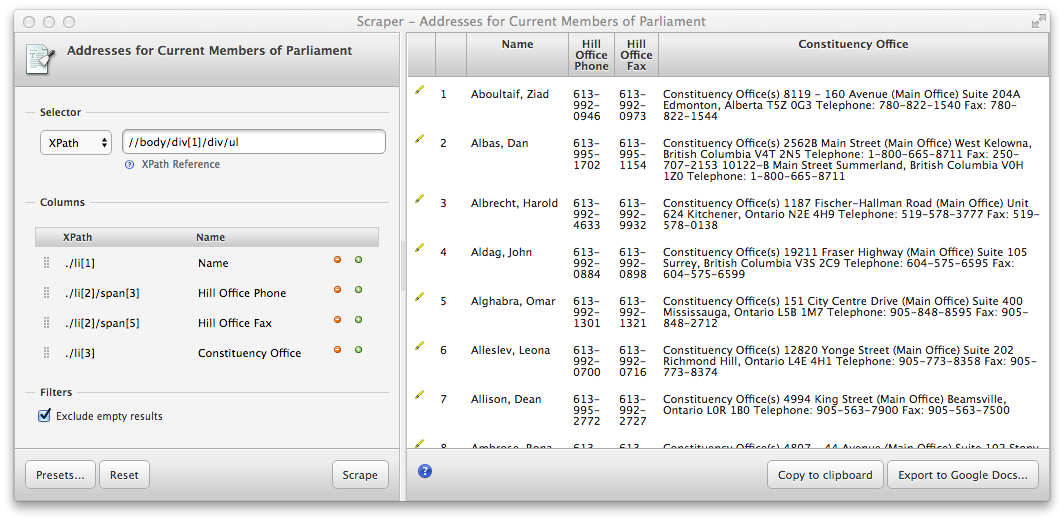
Keep working on the example above to add a column for the Hill Office phone number and fax number for each MP.
Solution
Add columns with the XPath query
./li[2]/span[3] -> Hill Office Phone ./li[2]/span[5] -> Hill Office Fax
Key Points
Data that is relatively well structured (in a table) is relatively easily to scrape.
More often than not, web scraping tools need to be told what to scrape.
XPath can be used to define what information to scrape, and how to structure it.
More advanced data cleaning operations are best done in a subsequent step.